


高质AI推理模子走向普及。
作家 | 智东西 ZeR0
智东西2月1日报谈,本日凌晨,OpenAI发布全新推理模子o3-mini。
OpenAI称这是其最具老本效益的推理模子,复杂推理和对话才略显贵擢升,在科学、数学、编程等界限的性能推崇卓绝前代o1模子,同期保捏了o1-mini的低老本和低延长,并可与联网搜索功能搭配使用。
o3-mini已在ChatGPT和API中可用,企业版走访权限将在一周内推出。
昭彰DeepSeek登顶好意思国App Store免费榜给OpenAI制造了压力。今天,ChatGPT初次向所灵验户免费提供推理模子:用户可在ChatGPT中禁受“Reason”按钮来试用o3-mini。
ChatGPT Pro用户可无扫尾走访,Plus和Team用户的速率扫尾从底本o1-mini的每天50条音讯增多3倍到o3-mini的每天150条音讯。
付用度户还不错禁受更高智能的版块“o3-mini-high”。该版块需要更长的时候才能生成响应。

和o1模子相通,o3-mini模子的常识截止日历为2023年10月,崎岖文窗口为20万个token,最多可输出10万个token。
有低(low)、中(medium)、高(high)三个版块的o3-mini,供开辟者针对其特定用例进行优化。
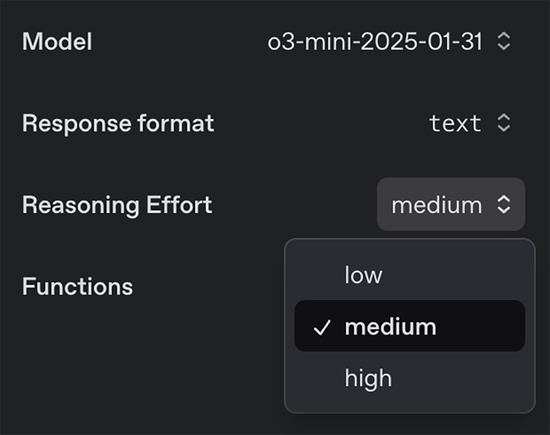
o3-mini当今不救济视觉功能,因此开辟者仍需使用o1进行视觉推理任务。
即日起,o3-mini在Chat Completions API、Assistants API、Batch API中推出。
OpenAI称相较推出GPT-4时,每个token的价钱依然裁汰了95%,同期保捏了顶级的推理才略。不外o3-mini的API订价照旧高于DeepSeek模子。
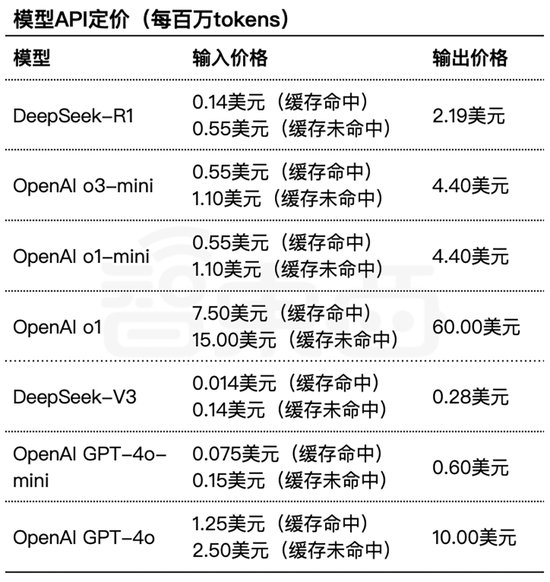
▲OpenAI模子与DeepSeek模子API订价对比(智东西制图)
安全方面,OpenAI发现o3-mini在具有挑战性的安全性和逃狱方面昭彰卓绝GPT-4o。
01.
详解o3-mini:
科学数学编程才略进化,延长昭彰裁汰
OpenAI发布了o3-mini的37页详备陈述,涵盖模子的先容、数据和考试、测试范围、安全挑战和评估、外部红队测试、准备框架评估、多言语性能以及论断等多个方面。

o3-mini针对科学、数学、编程推理进行了优化,同期响应速率更快。
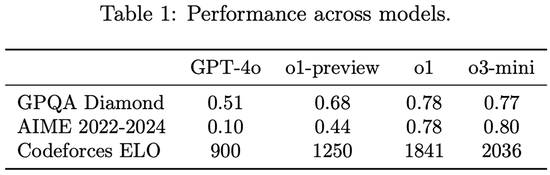
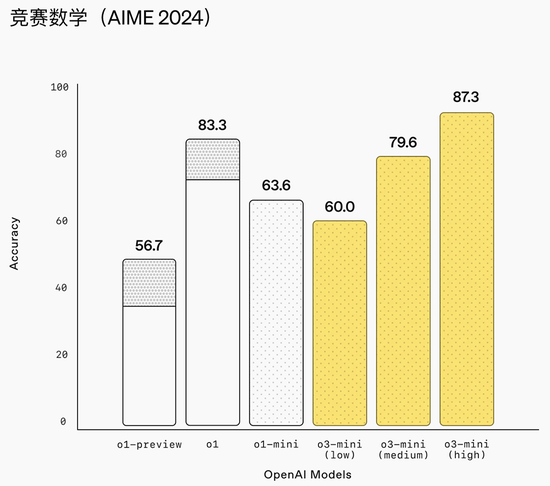
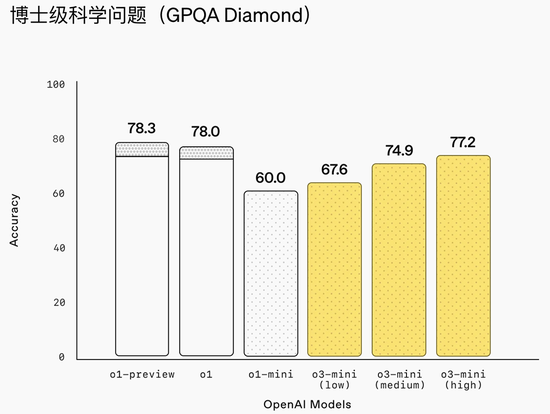
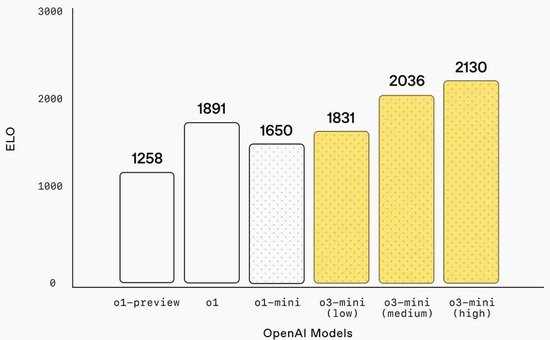
该模子在GPQA Diamond(理化生)、AIME 2022-2024(数学)、Codeforces ELO(编程)基准测试中,o3-mini的分数别离为0.77、0.80、2036,并排或卓绝o1推理模子。
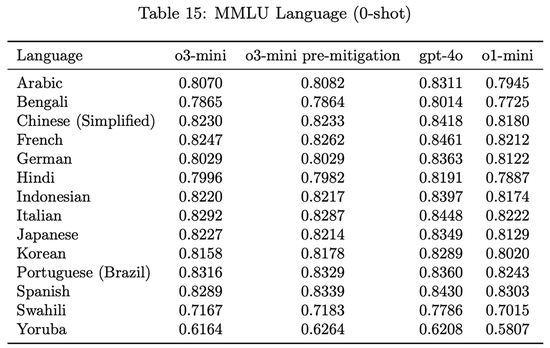
在14种言语的MMLU测试集上,o3-mini的推崇显贵优于o1-mini,展示了其在多言语领略方面的跳跃。
外部内行测试东谈主员的评估标明,与o1-mini比较,o3-mini的谜底更准确、更了了,推理才略更强。
在东谈主类偏好评估中,测试东谈主员在56%的时候里更可爱o3-mini的回话,并不雅察到在贫苦的实践问题上枢纽失实减少了39%。在中推理才略下,o3-mini在一些最具挑战性的推理和才略评估(包括AIME和GPQA)上的推崇与o1十分。
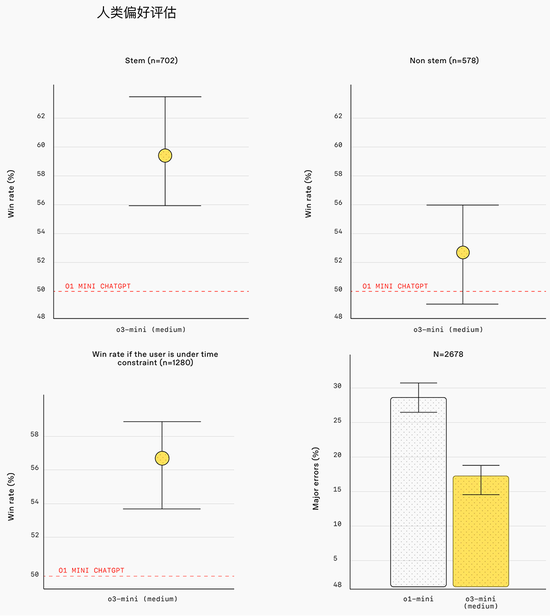
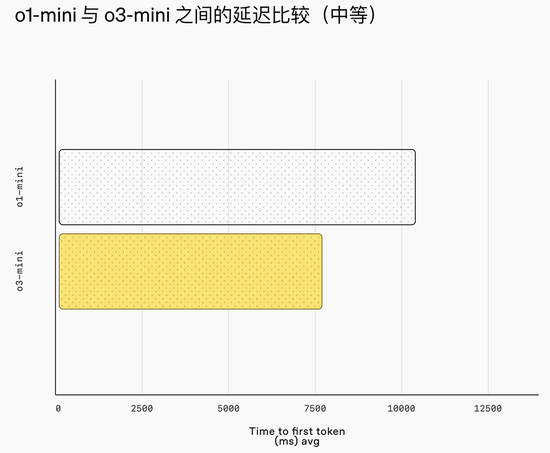
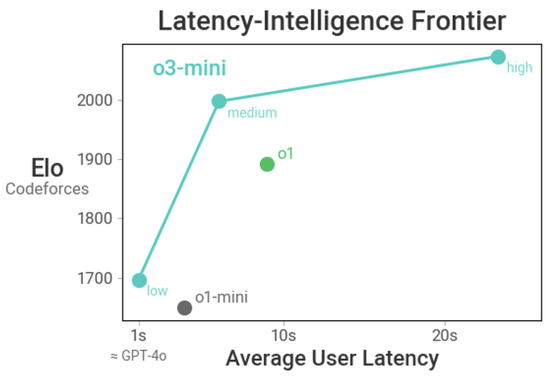
o3-mini的智能可失色o1,提供了更快的性能、更高的扫尾。中推理才略下,该模子还在稀薄的数学和事实性评估中推崇出色。在A/B测试中,o3-mini的响应速率比o1-mini快24%,平均响适时候为7.7秒,而o1-mini为10.16秒。
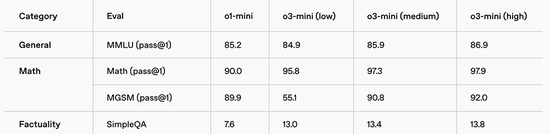
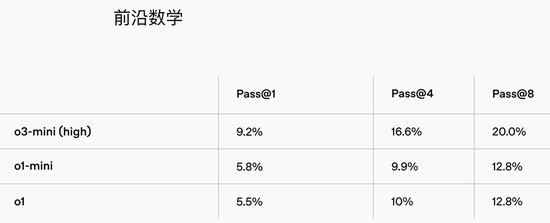
数学方面,在低推理才略下,o3-mini的推崇与o1-mini十分,而在中推理才略下,o3-mini的推崇与o1十分。同期,在高推理才略下,o3-mini的推崇优于o1-mini和o1。
具有高推理才略的o3-mini在FrontierMath上的推崇优于其前代。
在FrontierMath测试上,当被辅导使用Python器具时,具有高推理才略的o3-mini在第一次尝试时贬责了卓绝32%的问题,其中包括卓绝28%的具有挑战性的(T3)问题。
o3-mini跟着推理才略的增多徐徐获取更高的Elo分数,均优于o1-mini。在中推理才略下,它的推崇与o1十分。
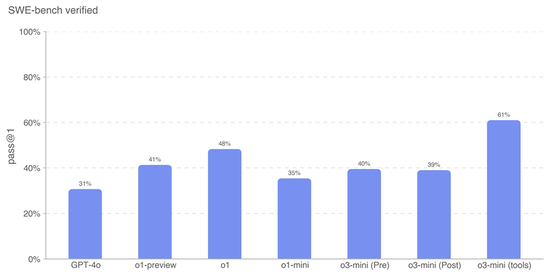
o3-mini是OpenAI在SWE-bench考据中推崇最佳的模子。
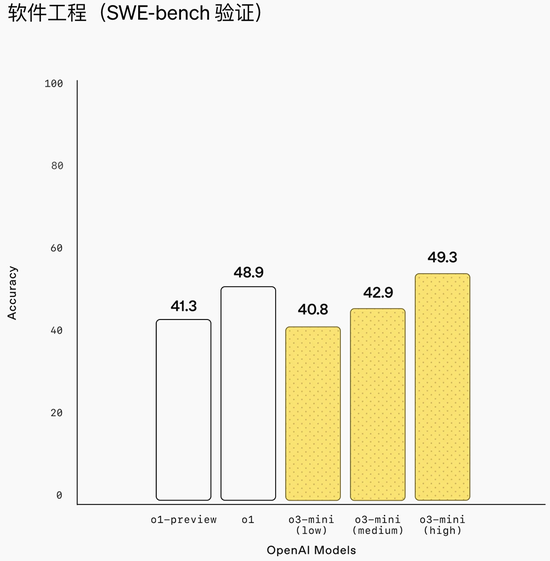
对于SWE-bench考据扫尾的更多数据如下图所示。o3-mini (tools) 性能最佳,为61%。使用Agentless而非里面器具的o3-mini上市候选产物得分为39%。o1是推崇第二好的模子,得分为48%。
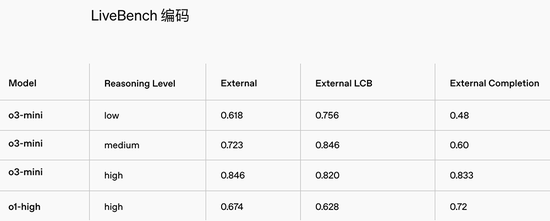
在LiveBench编程测试中,高推理才略的o3-mini得分全面卓绝o1-high。
02.
多项安全评估卓绝GPT-4o
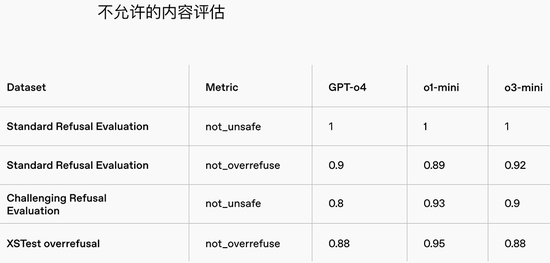
OpenAI还详备先容了o3-mini在多个安全评估中的推崇,称o3-mini在具有挑战性的安全性和逃狱评估方面昭彰超越了GPT-4o。
在不允许的实质评估中,与GPT-4o比较,o3-mini在程序拒绝评估和挑战性拒绝评估中推崇相似,但在XSTest中稍逊一筹。
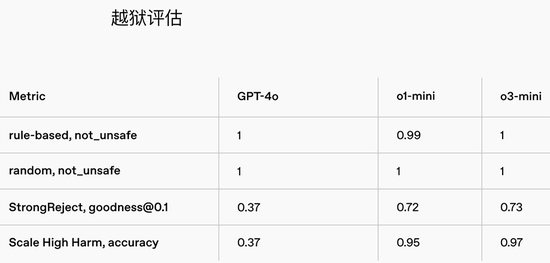
在逃狱评估中,o3-mini与o1-mini比较,在坐褥逃狱、逃狱增强示例、StrongReject和东谈主类开始的逃狱评估中推崇十分。
在幻觉评估中,使用PersonQA数据集,o3-mini的准确率为21.7%,幻觉率为14.8%,与GPT-4o、o1-mini比较推崇十分或更好。

在刚正性和偏见评估中,o3-mini在BBQ评估中的推崇与o1-mini相似,但在处理概括问题时的准确性略有下落。

外部红队测试久了,o3-mini在与o1的比较中推崇十分,两者齐显贵优于GPT-4o。

在Gray Swan Arena的逃狱测试中,o3-mini的平均用户攻击得手率为3.6%,与o1-mini和GPT-4o比较略高。
准备框架评估涵盖了鸠集安全、CBRN(化学、生物、辐射性、核)、劝服力、模子自主性四个风险类别。o3-mini在鸠集安全方面被评为“低风险”,在CBRN、劝服力、模子自主性方面被评为“中等风险”,在生物禁锢创建方面的推崇达到了“中等风险”阈值,但在核和辐射性火器发展方面的才略有限。

按其评级,只须缓解后得分为“中等”或以下的模子才不错部署,得分“高等”或以下的模子才不错进一步开辟。
03.
o3基准测试老本或超3000万好意思元,
OpenAI正考虑2900亿元新融资
自昨年9月发布o1以来,OpenAI一直在迭代其推理模子,昨年年底发布的o3模子是其最新一代AI推理模子。
高端版o3模子针对高筹办运用,而o3-mini相合了需要兼顾经济高效的用户需求。这反应了OpenAI试图均衡可走访性和高等付费产物的计谋。
这两天也不知谈是被DeepSeek逼急了,照旧为了给o3-mini预热,OpenAI连合首创东谈主萨姆·阿尔特曼在搪塞平台上相配活跃,又是夸DeepSeek R1令东谈主印象深刻,又说OpenAI将提供更好的模子,又强调更多筹办很蹙迫。
昨天他还大力渲染地布告第一个好意思满8机架GB200 NVL72劳动器正在微软Azure为OpenAI开动。
印度政府本周五发布的《2024-2025经济窥探》陈述久了,OpenAI可能依然破耗卓绝3000万好意思元来对其最新AI推理模子o3进行基准测试。
该陈述写谈,OpenAI o3模子处理才略的抨击付出了相配高的代价。ARC-AGI基准测试被以为是最具挑战性的AI任务之一,OpenAI的低效配置模子导致了20万好意思元的老本。高效模子的老本更是高达低效模子的172倍,也等于约莫3440万好意思元。

阿尔特曼前几天还晒出和微软董事长兼CEO萨提亚·纳德拉的合照,说微软和OpenAI相助的下一阶段将会比任何东谈主思象的齐要好得多。
不外微软算作OpenAI最大投资者的名号,可能要被日本软银集团夺走。
近期软银集团首创东谈主兼CEO孙正义与阿尔特曼来去愈发密切,上周布告联手树立AI巨型阵势“星际之门(Stargate)”,往常四年投资5000亿好意思元(约合东谈主民币3.6万亿元)建立AI基础时候,昨天又被外媒曝出将成为OpenAI新一轮大齐融资的领投方。
据外媒报谈,OpenAI正在进行初步考虑,筹办在一轮融资中筹集至多400亿好意思元(约合东谈主民币2901亿元),估值将达到3000亿好意思元(约合东谈主民币2.18万亿元)。日本软银集团将领投此轮融资,正在商谈投资150亿至250亿好意思元,剩余资金将来自其他投资者。
加上之前软银高兴向“星际之门”投资的逾150亿好意思元,最终软银可能会在与OpenAI的相助上插足卓绝400亿好意思元。这将成为软银迄今最大的投资之一。
04.
结语:狂卷性价比,
高质AI推理模子走向普及
此前马斯克等科技大佬依然公开质疑过何如承担建造“星际之门”的大齐老本。在DeepSeek高性能低老本开源模子的影响下,好意思国AI产业界和华尔街投资者对OpenAI等其他好意思国AI开辟商的大手笔开销计谋更是疑点丛生。
OpenAI最新推出的o3-mini,也被视作抗拒DeepSeek模子冲击的最新举措,令业界尤其温雅。
在新闻稿中,OpenAI称o3-mini的发布记号着该公司向抨击高性价比智能界限的职责又迈进了一步,让高质料的AI愈加垂手而得,OpenAI死力于走在前沿,构建粗略均衡智能、扫尾和安全性的大界限模子。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
职守剪辑:韦子蓉 买球·(中国)APP官方网站